TL-B Language
TL-B (Type Language - Binary) serves to describe the type system, constructors and existing functions. For example, we
can use TL-B schemes to build binary structures associated with TON Blockchain. Special TL-B parsers can read schemes to
deserialize binary data into different objects. TL-B describes data schemes for Cell objects. If you not familiar
with Cells, please read Cell & Bag of Cells(BOC) article.
Overview
We refer to any set of TL-B constructs as TL-B documents. A TL-B document usually consists of declarations of types (
i.e. their constructors) and functional combinators. The declaration of each combinator ends with a semicolon (;).
Here is an example of a possible combinator declaration:
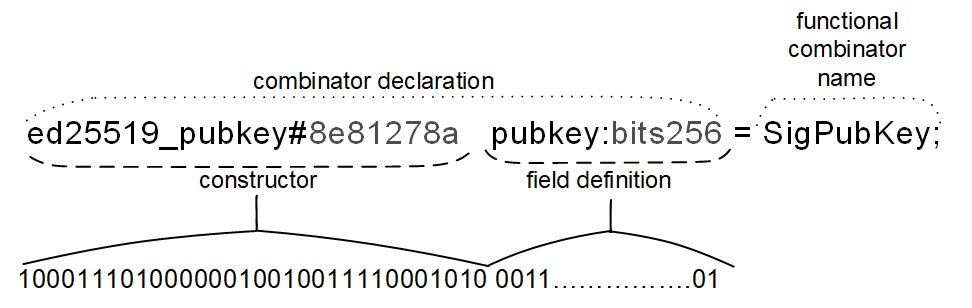
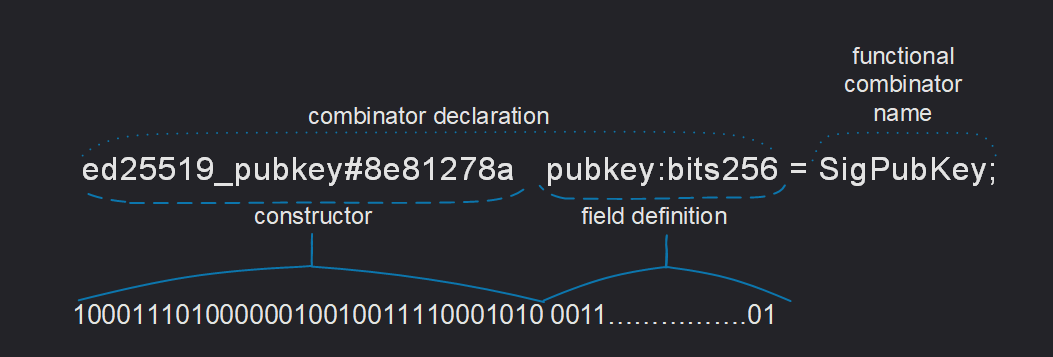
Constructors
The left-hand side of each equation describes the way to define, or serialize, a value of the type indicated on the right-hand side. Such a description begins with the name of a constructor.

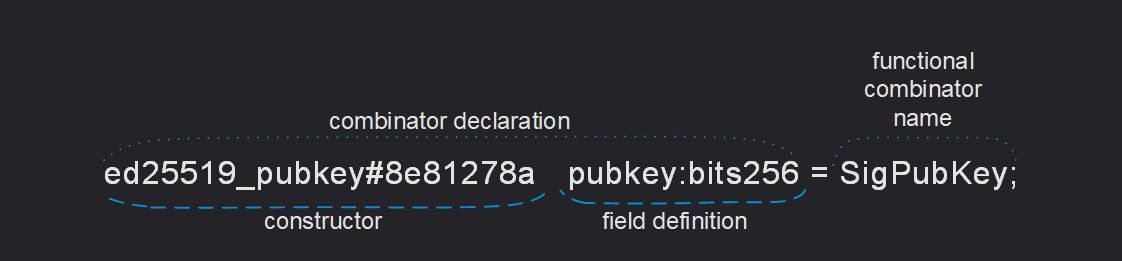
Constructors are used to specify the type of combinator, including the state at serialization. For example, constructors
can also be used when you want to specify an op(operation code) in query to a smart contract in TON.
// ....
transfer#5fcc3d14 <...> = InternalMsgBody;
// ....
- constructor name:
transfer - constructor prefix code:
#5fcc3d14
Notice, every constructor name immediately followed by an optional constructor tag, such as #_ or $10, which
describes the bitstring used to encode (serialize) the constructor in question.
message#3f5476ca value:# = CoolMessage;
bool_true$0 = Bool;
bool_false$1 = Bool;
The left-hand side of each equation describes the way to define, or serialize, a value of the type indicated on the
right-hand side. Such a description begins with the name of a constructor, such as message or bool_true, immediately
followed by an optional constructor tag, such as #3f5476ca or $0, which describes the bits used to encode (
serialize)
the constructor in question.
| constructor | serialization |
|---|---|
some#3f5476ca | 32-bit uint serialize from hex value |
some#5fe | 12-bit uint serialize from hex value |
some$0101 | serialize 0101 raw bits |
some or some# | serialize crc32(equation) \| 0x80000000 |
some#_ or some$_ or _ | serialize nothing |
Constructor names (some in this example) are used as variables in codegen. For example:
bool_true$1 = Bool;
bool_false$0 = Bool;
Type Bool has two tags 0 and 1. Codegen pseudocode might look like:
class Bool:
tags = [1, 0]
tags_names = ['bool_true', 'bool_false']
If you don't want to define any name for current constructor, just pass _, e.g. _ a:(## 32) = 32Int;
Constructor tags may be given in either binary (after a dollar sign) or hexadecimal notation (after a hash sign). If a
tag is not
explicitly provided, the TL-B parser must compute a default 32-bit constructor tag by hashing with CRC32 algorithm
the text of the “equation” with | 0x80000000 defining this constructor in a certain fashion. Therefore, empty tags
must be explicitly provided by #_ or $_.
This tag willies used to guess current type of bitstring in deserialization process. E.g. we have 1 bit bitstring 0,
if we tell TLB to parse this bitstring in type of Bool it will parse it as Bool.bool_false.
Let's say we have more complex examples:
tag_a$10 val:(## 32) = A;
tag_b$00 val(## 64) = A;
If we parse 1000000000000000000000000000000001 (1 and 32 zeroes and 1) in TLB type A - firstly we need to get first
two bits to define tag. In this example 10 is two first bits and they represent tag_a. So now we know that next 32
bits are val variable, 1 in our example. Some "parsed" pseudocode variables may look like:
A.tag = 'tag_a'
A.tag_bits = '10'
A.val = 1
All constructor names must be distinct and constructor tags for the same type must constitute a prefix code (otherwise the deserialization would not be unique); i.e. no tag can be a prefix of any other in same type.
Maximum number of constructors per one type: 64
Maximum bits for tag: 63
example_a$10 = A;
example_b$01 = A;
example_c$11 = A;
example_d$00 = A;
Codegen pseudocode might look like:
class A:
tags = [2, 1, 3, 0]
tags_names = ['example_a', 'example_b', 'example_c', 'example_d']
example_a#0 = A;
example_b#1 = A;
example_c#f = A;
Codegen pseudocode might look like:
class A:
tags = [0, 1, 15]
tags_names = ['example_a', 'example_b', 'example_c']
If you use hex tag, keep in mind that it will be serialized as 4 bits for each hex symbol. Maximum value is 63-bit
unsigned integer. This means:
a#32 a:(## 32) = AMultiTagInt;
b#1111 a:(## 32) = AMultiTagInt;
c#5FE a:(## 32) = AMultiTagInt;
d#3F5476CA a:(## 32) = AMultiTagInt;
| constructor | serialization |
|---|---|
a#32 | 8-bit uint serialize from hex value |
b#1111 | 16-bit uint serialize from hex value |
c#5FE | 12-bit uint serialize from hex value |
d#3F5476CA | 32-bit uint serialize from hex value |
Also hex values allowed both in upper and lower case.
More about hex tags
In addition to the classic hex tag definition, a hexadecimal number can be followed by the underscore character. This means that the tag is equal to the specified hexadecimal number without the least significant bit. For example there is a scheme:
vm_stk_int#0201_ value:int257 = VmStackValue;
And the tag is not actually equal to 0x0201. To compute it we need to remove LSb from the binary representation of 0x0201:
0000001000000001 -> 000000100000000
So the tag equals to the 15-bit binary number 0b000000100000000.
Field definitions
The constructor and its optional tag are followed by field definitions. Each field definition is of the
form ident:type-expr, where ident is an identifier with the name of the field (replaced by an underscore for
anonymous fields), and type-expr is the field’s type. The type provided here is a type expression, which may include
simple types, parametrized types with suitable parameters or complex expressions.
Simple types
_ a:# = Type;-Type.ahere is 32-bit integer_ a:(## 64) = Type;-Type.ahere is 64-bit integer_ a:Owner = NFT;-NFT.ahere isOwnertype_ a:^Owner = NFT;-NFT.ahere is cell ref toOwnertype meansOwneris stored in next cell reference.
Anonymous fields
_ _:# = A;- first field is anonymous 32-bit integer
Extend cell with references
_ a:(##32) ^[ b:(##32) c:(## 32) d:(## 32)] = A;
- If for some reason we want to separate some fields to another
cell we can use
^[ ... ]syntax. In this exampleA.a/A.b/A.c/A.dare 32-bit unsigned integers, butA.ais stored in first cell, andA.b/A.c/A.dare stored in next cell (1 ref)
_ ^[ a:(## 32) ^[ b:(## 32) ^[ c:(## 32) ] ] ] = A;
- Chain of references are also allowed. In this example each of
variables (
a,b,c) are stored in separated cells
Parametrized types
Suppose we have IntWithObj type:
_ {X:Type} a:# b:X = IntWithObj X;
Now we can use it in other types:
_ a:(IntWithObj uint32) = IntWithUint32;
Complex expressions
- Conditional fields (only for
Nat) (E?Tmeans if expressionEis True than field has typeT)In_ a:(## 1) b:a?(## 32) = Example;Exampletype variablebserialized only ifais1
Multiply expression for tuples creation (
x * Tmeans create tuple of lengthxof typeT):a$_ a:(## 32) = A;
b$_ b:(2 * A) = B;_ (## 1) = Bit;
_ 2bits:(2 * Bit) = 2Bits;Bit selection (only for
Nat) (E . Bmeans take bitBofNatE)_ a:(## 2) b:(a . 1)?(## 32) = Example;In
Exampletype variablebserialized only if second bitais1
- Other
Natoperators also allowed (lookAllowed contraints)
Note: you can combine several complex expressions:
_ a:(## 1) b:(## 1) c:(## 2) d:(a?(b?((c . 1)?(## 64)))) = A;
Built-in types
#-Nat32 bits unsigned integer## x-Natwithxbits#< x-Natless thanxbit unsigned integer stored aslenBits(x - 1)bits, up to 31 bits#<= x-Natless or equal thanxbit unsigned integer stored aslenBits(x)bits, up to 32 bitsAny/Cell- rest of cell bits&refsInt- 257 bitsUInt- 256 bitsBits- 1023 bitsuint1-uint256- 1 - 256 bitsint1-int257- 1 - 257 bitsbits1-bits1023- 1 - 1023 bitsuint X/int X/bits X- same asuintXbut you can use parametrizedXin this types
Constraints
_ flags:(## 10) { flags <= 100 } = Flag;
Nat fields allowed in constraints. In this example { flags <= 100 } constraint means that flags variable is less
or
equal 100.
Allowed contraints: E | E = E | E <= E | E < E | E >= E | E > E | E + E | E * E | E ? E
Implicit fields
Some fields may be implicit. Their definitions are surrounded by curly
brackets({, }), which indicate that the field is not actually present in the serialization, but that its value must
be deduced from other data (usually the parameters of the type being serialized). Example:
nothing$0 {X:Type} = Maybe X;
just$1 {X:Type} value:X = Maybe X;
_ {x:#} a:(## 32) { ~x = a + 1 } = Example;
Parametrized types
Variables — i.e. the (identifiers of the) previously
defined fields of types # (natural numbers) or Type (type of types) — may be used as parameters for the parametrized
types. The serialization process recursively serializes each field according to its type and the serialization of a
value ultimately consists of the concatenation of bits representing the constructor (i.e. the constructor tag) and
the field values.
Natural numbers (Nat)
_ {x:#} my_val:(## x) = A x;
Means that A is parametrized by x Nat. In deserialization process we will fetch x-bit unsigned integer E.g.:
_ value:(A 32) = My32UintValue;
Means than in deserialization process of My32UintValue type we will fetch 32-bit unsigned integer (because of 32
parameter to A type)
Types
_ {X:Type} my_val:(## 32) next_val:X = A X;
Means that A is parametrized by X type. In deserialization process we will fetch 32-bit unsigned integer and than
parse
bits&refs of type X.
Usage example of such parametrized type can be:
_ bit:(## 1) = Bit;
_ 32intwbit:(A Bit) = 32IntWithBit;
In this example we pass type Bit to A as parameter.
If you don't want to define type, but want to deserialize by this scheme you may use Any word:
_ my_val:(A Any) = Example;
Means that if we deserialize Example type we will fetch 32-bit integer and then rest of cell (bits&refs) to my_val.
You can create complex types with several parameters:
_ {X:Type} {Y:Type} my_val:(## 32) next_val:X next_next_val:Y = A X Y;
_ bit:(## 1) = Bit;
_ a_with_two_bits:(A Bit Bit) = AWithTwoBits;
Also you can use partial apply on such parametrized types:
_ {X:Type} {Y:Type} v1:X v2:Y = A X Y;
_ bit:(## 1) = Bit;
_ {X:Type} bits:(A Bit X) = BitA X;
Or even parametrized types itself:
_ {X:Type} v1:X = A X;
_ {X:Type} d1:X = B X;
_ {X:Type} bits:(A (B X)) = AB X;
NAT fields usage for parametrized types
You can use fields defined previously like parameters to types. Serialization will be determinate in runtime.
Simple example:
_ a:(## 8) b:(## a) = A;
This means that we store size of b field inside of a field. So when we want to serialize type A we need to load 8
bit unsigned integer of a field and then use this number to determinate size of b field.
This strategy works for parametrized types as well:
_ {input:#} c:(## input) = B input;
_ a:(## 8) c_in_b:(B a) = A;
Expression in parametrized types
_ {x:#} value:(## x) = Example (x * 2);
_ _:(Example 4) = 2BitInteger;
In this example Example.value type is determinate in runtime.
In 2BitInteger definition we set value Example 4 type. To determinate this type we use Example (x * 2)
definition and calculate x by formula (y = 2, z = 4):
static inline bool mul_r1(int& x, int y, int z) {
return y && !(z % y) && (x = z / y) >= 0;
}
We can also use add operator:
_ {x:#} value:(## x) = ExampleSum (x + 3);
_ _:(ExampleSum 4) = 1BitInteger;
In 1BitInteger definition we set value ExampleSum 4 type. To determinate this type we use ExampleSum (x + 3)
definition and calculate x by formula (y = 3, z = 4):
static inline bool add_r1(int& x, int y, int z) {
return z >= y && (x = z - y) >= 0;
}
Negate operator (~)
Some occurrences of “variables” (i.e. already-defined fields) are prefixed by a tilde(~). This indicates that the
variable’s occurrence is used in the opposite way to the default behavior: on the left-hand side of the equation, it
means that the variable will be deduced (computed) based on this occurrence, instead of substituting its previously
computed value; in the right-hand side, conversely, it means that the variable will not be deduced from the type being
serialized, but rather that it will be computed during the deserialization process. In other words, a tilde transforms
an “input argument” into an “output argument” or vice versa.
Simple example for negate operator is definition of new variable base on another variable:
_ a:(## 32) { b:# } { ~b = a + 100 } = B_Calc_Example;
After definition, you can use new variable for passing it to Nat types:
_ a:(## 8) { b:# } { ~b = a + 10 }
example_dynamic_var:(## b) = B_Calc_Example;
The size of example_dynamic_var will be computed in runtime, when we load a variable and use it value for
determination of example_dynamic_var size.
Or to other types:
_ {X:Type} a:^X = PutToRef X;
_ a:(## 32) { b:# } { ~b = a + 100 }
my_ref: (PutToRef b) = B_Calc_Example;
Also you can define variables with negate operator in add or multiply complex expressions:
_ a:(## 32) { b:# } { ~b + 100 = a } = B_Calc_Example;
_ a:(## 32) { b:# } { ~b * 5 = a } = B_Calc_Example;
Negate operator (~) in type definition
_ {m:#} n:(## m) = Define ~n m;
_ {n_from_define:#} defined_val:(Define ~n_from_define 8) real_value:(## n_from_define) = Example;
Assume we have class Define ~n m which takes m and compute n loading it from m bit unsigned integer.
In Example type we store variable computed by Define type into n_from_define, also we know that it's 8 bit
unsigned integer, because we apply Define type with Define ~n_from_define 8. Now we can use n_from_define variable
in other types to determinate serialization process.
This technic lead to more complex type definitions (such as Unions, Hashmaps).
unary_zero$0 = Unary ~0;
unary_succ$1 {n:#} x:(Unary ~n) = Unary ~(n + 1);
_ u:(Unary Any) = UnaryChain;
This is example has good explanation in TL-B Types
article. The main idea here is that UnaryChain will recursively deserialize until reach of unary_zero$0 (because we
know last element of Unary X type by definition unary_zero$0 = Unary ~0; and X is calculated in runtime
due Unary ~(n + 1) definition).
Note: x:(Unary ~n) means that n is defined in process of serialization of Unary class.
Special types
Currently, TVM allow types of cells:
- Ordinary
- PrunnedBranch
- Library
- MerkleProof
- MerkleUpdate
By default, all cells are Ordinary. And all cells described in tlb are Ordinary.
To allow load of special types in constructor you need to add ! before constructor.
Example:
!merkle_update#02 {X:Type} old_hash:bits256 new_hash:bits256
old:^X new:^X = MERKLE_UPDATE X;
!merkle_proof#03 {X:Type} virtual_hash:bits256 depth:uint16 virtual_root:^X = MERKLE_PROOF X;
This technic allow codegen code to mark SPECIAL cells when you want to print structure, also it allow to correctly
validate structures with special cells.
Several instances for one type without constructor uniqueness tag check
It's allowed to create several instances of one type depending only on type parameters. In this way of definition constructor tag unique check will not be applied.
Example:
_ = A 1;
a$01 = A 2;
b$01 = A 3;
_ test:# = A 4;
Means that actual tag for deserialization will be determinate by A type parameter:
# class for type `A`
class A(TLBComplex):
class Tag(Enum):
a = 0
b = 1
cons1 = 2
cons4 = 3
cons_len = [2, 2, 0, 0]
cons_tag = [1, 1, 0, 0]
m_: int = None
def __init__(self, m: int):
self.m_ = m
def get_tag(self, cs: CellSlice) -> Optional["A.Tag"]:
tag = self.m_
if tag == 1:
return A.Tag.cons1
if tag == 2:
return A.Tag.a
if tag == 3:
return A.Tag.b
if tag == 4:
return A.Tag.cons4
return None
Same works with several parameters:
_ = A 1 1;
a$01 = A 2 1;
b$01 = A 3 3;
_ test:# = A 4 2;
Please, keep in mind that when you add parametrized type definition, tags between predefined type definition (a
and b in our example) and
parametrized type definition (c in our example) must be unique:
Not valid example:
a$01 = A 2 1;
b$11 = A 3 3;
c$11 {X:#} {Y:#} = A X Y;
Valid example:
a$01 = A 2 1;
b$01 = A 3 3;
c$11 {X:#} {Y:#} = A X Y;
Comments
Comments are the same as in C++
/*
This is
a comment
*/
// This is one line comment
Useful sources
Documentation provided by Disintar team.